|
More than 20 years ago I had a small card called "RAM" which was the acronym for "Remote Automatic Mouth" for my beloved Apple-II - this little card was a speech synthesizer and I had much fun with it, writing programs to control this card. A couple of weeks ago I found a chip called Speakjet which is feature for example in the following group: http://groups.yahoo.com/group/speakjet This integrated circuit contains nearly everything that is necessary to build a speech synthesizer which can be controlled by a simple serial line interface. I always hoped to get a DECtalk speech synthesizer for my VAX FAFNER to make it talk to me and eventually give me a phone call when anything at home is going wrong when I am abroad, I decided to stop waiting for a DECtalk system and instead build my own speech synthesizer using the Speakjet chip. |
||

|
The picture on the left shows my Dragontalk system based on this chip. The front plate holds all control and connection elements. Prominent in the middle is the SUB-D 25 serial line jack, on the far left is the power supply connector while on the right a 6.3mm audio connector can be seen. The switches are "Power", "Reset (green)" and "Volume". The LEDs on top of the frontplate are "Power", "Ready", "Receive Data", "Buffer Full", "Speaking" and "Test". |
|
|
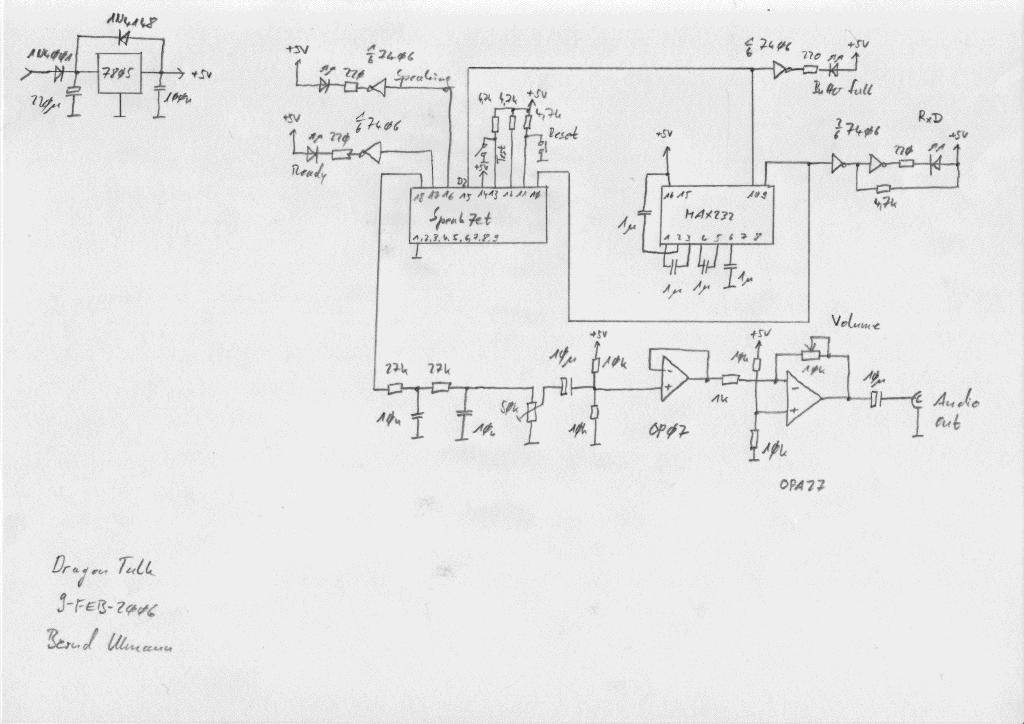
Since the chip contains most of what is needed, the necessary glue circuitry is very simple as the picture on the right shows. There is a MAX-232 driver for the serial line interface to allow using proper RS-232 signal levels, a 74LS06 open collector driver for controlling the LEDs, the Speakjet chip itself, and two operational amplifiers OP07 and OPA27 for amplifying the audio output signal to a level suitable for a headset or the line input of a normal audio amplifier. |

|
|
|
The complete schematic of the speech synthesizer can be seen on the left (click on the picture to get a high resolution version of the schematics - if you prefer a PDF version, have a look here). The Speakjet chip which is available in Germany for example from http://www.robotikhardware.de costs about 25-30 EUR. All other components of the synthesizer are very cheap, the enclosure being the biggest item. Unfortunately I forgot to draw the two signal lines to the SUB-D 25 RS-232 connector. Pin 3 (RxD) of this connector has to be connected to pin 8 of the MAX-232 while Pin 5 (CTS) goes to pin 7 of the MAX-232 - sorry for the omission. |
|
|
Now that I had a speech synthesizer I had to figure out what to do next. The Speakjet chip is a phonemgenerator (more exactly it generates allophones, but since I am not a linguist, I do not really care about this) so it requires as input a control sequence specifying a sequence of phonemes it should generate. To test this I wrote a very simple test program in Perl which made FAFNER say "THIS IS FAFNER SPEAKING. FAFNER IS A VAX RUNNING VMS." - the phoneme sequence for this was handcoded and the last thing I did the night after completing the hardware. You may find the Perl source code here: fafner.perl. As a sequence of phonemes the above sentence looks like this:
DH IH SE P5 _
IH SE P5 _
FF AW FF NE EYRR P5 _
SE PE IY KE IY NGE _
P3 _
FF AW FF NE EYRR P5 _
IH SE P5 _
EYIY P5 _
VV AY KE SE P5 _
RR AY NE IY NGE P5 _
VV IY P6 EH MM MM P6 EY SO P6 _
The notation is quite closely related to that used in the Speakjet documentation. The only aberrations from this are the symbols Px which denote pauses and the underscore which denotes the end of a word to the program sending the phonem sequence to the speech synthesizer. The synthesizer chip features a 64 byte on chip buffer for data received via its serial line interface. Running at a speed of 9600 baud this buffer will fill up in a couple of milliseconds causing data loss. To prevent this the Speakjet chip has an output signal which goes high when the on-chip buffer is 50 percent filled. This signal can be used for a simple hardware handshake mechanism using the CTS-line of the serial interface to the host computer (the schematics above support this variant). Since FAFNER is a very large VAX without any directly attached serial line interfaces (apart from the console interface) I was forced to use a DECserver for getting some serial lines. The problem resulting from using a DECserver is that there are lots of buffers between the program running on the VAX and the serial line itself. When the Speakjet removes its CTS-signal, there still is enough data on its way to flood the buffer before the hardware handshake signal will be recognized. Thus I decided to ignore the hardware handshaking and just wait just the right amount of time which is easy since the duration of every phoneme the synthesizer can generate can be found in the accompanying documentation. So the Perl program first creates a hash in which all available allophones are stored with their associated control values and their duration - this looks like this:
my %allophone =
(
P0 => [0, 0], # Pauses
P1 => [1, 100],
P2 => [2, 200],
P3 => [3, 700],
P4 => [4, 30],
P5 => [5, 60],
P6 => [6, 90],
FAST => [7, 0], # Play next phoneme with double speed
SLOW => [8, 0], # Play next phoneme 1.5 times slower
STRS => [9, 0], # Play next phoneme with a bit stress in the voice
RELX => [10, 0], # Relax again...
IY => [128, 70],
IH => [129, 70],
EY => [130, 70],
... ... ... ...
Using this information it is easy to accumulate the duration of all phonemes in a word, send the proper control sequence to the Speakjet and then wait as many milliseconds as necessary, so the main output loop looks like this:
my ($duration, $word) = (0, '');
for my $phoneme (@data)
{
if ($phoneme eq '_')
{
printf ("%60s: %d ms\n", $word, $duration) if $debug;
usleep ($duration * 1000);
($duration, $word) = (0, '');
}
else
{
$word .= $phoneme;
$duration += $allophone{$phoneme}[1];
print SPEAK chr($allophone{$phoneme}[0]);
}
}
This works very reliably and can be implemented easily. The only drawback of this program is that it requires one to generate the phoneme sequence by hand which is rather cumbersome and errorprone (on the other hand you will hear some really funny words which are no words at all during developing phoneme sequences :-) ). What I need is a program which accepts english texts in ASCII format, transforms these into a phoneme sequence suitable for the Speakjet and send this information to the synthesizer. Obviously this is quite hard - developing an algorithm to convert normal written English into a phoneme sequence is way too difficult for a small project like this. Fortunately, there are two publicly available pronounciation dictionaties for English words. One of these is called MOBYPRON and was developed by Grady Ward. A short description of the structure of this dictionary can be found here. I found using MOBYPRON quite complicated (although there was a very interesting article in a former Perl Journal in which this dictionary was used to find rhymes in English poems) and decided to use the Carnegie Mellon Pronouncing Dictionary version 0.3 which can be found locally here (about 3.2 MB). It looks like this:
ACCOMPLICE AH0 K AA1 M P L AH0 S
ACCOMPLICES AH0 K AA1 M P L AH0 S AH0 Z
ACCOMPLISH AH0 K AA1 M P L IH0 SH
ACCOMPLISHED AH0 K AA1 M P L IH0 SH T
ACCOMPLISHES AH0 K AA1 M P L IH0 SH IH0 Z
ACCOMPLISHING AH0 K AA1 M P L IH0 SH IH0 NG
ACCOMPLISHMENT AH0 K AA1 M P L IH0 SH M AH0 N T
ACCOMPLISHMENTS AH0 K AA1 M P L IH0 SH M AH0 N T S
It contains a list of words (about 110000!) with their pronounciation - this pronounciation makes use of 69 different short cuts (which are completely incompatible with the short cuts used be the Speakjet chip). Using this dictionary I wrote another Perl program which reads in the CMU dictionary, builds a lookup hash containing all words of the dictionary with their pronounciation which has been translated to Speakjet compatible sequences while building this hash. After perfoming these initial steps, the program prompts the user for the name of a file containing English text. It will then translate this text into a phoneme sequence and write this sequence to an output file. If it encounters a word which can not be found in the underlying dictionary it will generate a beep tone instead of the word (this has just been a short work around - the program could easily be modified to spell unknown words which would be better than a beep at least). The following example may clearify this procedure. A file called demo.txt containing the text
This is a short example of the automatic conversion
of english text data to phoneme sequences.
has been used as input to the conversion program
txt2phon.pl which in turn created an output
file demo.pho with the following content:
DH IH SE P5 _
IH SE P5 _
EY P5 _
SH AW AW RR TT P5 _
IH GE ZZ AY MM PO EY LE P5 _
UX VV P5 _
DH EY P5 _
AW TT EY MM AY TT IH KE P5 _
KE EY NE VV AXRR ZH EY NE P5 _
UX VV P5 _
IH NGE GE LE IH SH P5 _
TT EH KE SE TT P5 _
ED EYIY TT EY P5 _
TT UW UW P5 _
M0 P5 _
SE IY IY KE WW EY NE SE EY ZZ P5 _
P3 _
As you can see, the dictionary does not contain the word "phoneme" -
all other words have been translated flawlessly.
This sequence of phonemes can not be used as input for the program speak_translated.pl which handles the communication with the speech synthesizer. | ||